
Interaction Through Cognitive Architecture
Development of humanoid robots has to address two vital aspects, namely physical appearance and gestures, that will allow the machines to closely resemble humans. Other aspects such as “social” and “emotional” will enable human-machine interaction to be as natural as possible. The field of robotics has long been investigating how effective interaction between humans and autonomous and intelligent mechanical system can be possible (Goodrich & Schultz., 2007). Several distinctive features have been determined depending on whether a robot that acts as an assistant (for example, in the course of a business) or as a companion is required. In the case of humanoid robots, the human appearance and behavior may be very closely linked and integrated if you adopt a cognitive architecture that can take advantage of the natural mechanisms for exchange of information with a human. The robot that cooperates in the execution of an activity would benefit from the execution of its tasks if it had a mechanism that is capable of recognizing and understanding human activity and intention (Kelley et al., 2010), with perhaps the possibility of developing imitation learning by observation mechanisms.
On the other hand, if we consider the robot as a partner, then it plays an important role in sharing the emotional aspects: it is not essential to equip the robot with emotions, but it is important that it can “detect” human emotional states (Malatesta et al. 2009).
The cognitive architectures allow software to deal with problems that require contributions from both the cognitive sciences and robotics, in order to achieve social behavior typical of the human being, which would otherwise be difficult to integrate into traditional systems of artificial intelligence. Several cognitive models of the human mind can find common ground and experimental validation using humanoid agents. For example, if we approach the study of actions and social interactions involving “embodied” agents, the concept of motor resonance investigated in humans may play an important role (Chaminade & Cheng, 2009) to achieve sophisticated, yet simple to implement, imitative behaviors, learning by demonstration, and understanding of the real scene.
In recent years, there is often talk of mirror neurons, which are evidence of the physiological motor resonance at the cellular level with regard to action, action understanding and imitation. But the resonance is applicable in other contexts such as cognitive emotions, the sensations of physical pain, and in various components of the actions of agents interacting socially (Barakova & Lourens, 2009; Fogassi, 2011).
Cognitive models proposed would make the humanoid robot capable of overcoming the so-called “Uncanny Valley of eeriness” (Saygin et al., 2011), by allowing the humanoid is perceived by human beings not as artificial machine but as a credible social interacting entity. In this sense, the recent experimental data have confirmed the importance of “natural” movements (Saygin et al., 2011) that are expected from the observation of a robot with human features, even if it is a process yet to fully understand, that continually generate predictions about the environment, and compares them with internal states and models. Mirror neurons are assumed to be the neural basis for understanding the goals and intentions (Fogassi 2011), allowing for the prediction of the actions of the individual who is observed, and its intentions. Various studies indicate that they are also involved in the system of empathy, and emotional contagion (Hatfield et al. 1994), explaining that the human tendency to automatically mimic and synchronize facial expressions, vocalizations, postures, and movements with those of another person.
The classical approach in robotics based on the perception-reasoning-action loop has evolved towards models that unify perception and action, such as the various cognitive theories arising from the Theory of Event Coding (Hommel et al., 2001). Similarly, the objectives are integrated with the intentions, and emotions with reasoning and planning.
An approach that considers the human-robot interaction based on affective computing and cognitive architectures, can address the analysis and reproduction of social processes (and not only) that normally occur between humans, so that a social structure can be created which includes the active presence of a humanoid. Just as a person or group influences the emotions and the behavior of another person or group (Barsade, 2002), the humanoid could play a similar role in owning their own emotional states and behavioral attitudes, and by understanding the affective states to humans to be in “resonance” with them.
The purpose of this chapter is to consider the two aspects, intentions and emotions, simultaneously: discussing and proposing solutions based on cognitive architectures (such as in Infantino et al., 2008) and comparing them against recent literature including areas such as conversational agents (Cerezo et al., 2008).
The structure of the chapter is as follows: firstly, an introduction on the objectives and purposes of the cognitive architectures in robotics will be presented; then a second part on the state of the art methods of detection and recognition of human actions, highlighting those more suitably integrated into an architecture cognitive; a third part on detecting and understanding emotions, and a general overview of effective computing issues; and finally the last part presents an example of architecture that extends on the one presented in (Infantino et al., 2008), and a discussion about possible future developments.
Cognitive architectures
To achieve the advanced objective of human-robot interaction, many researchers have developed cognitive systems that consider sensory, motor and learning aspects in a unified manner. Dynamic and adaptive knowledge also needs to be incorporated, basing it on the internal representations that are able to take into account variables contexts, complex actions, goals that may change over time, and capabilities that can extend or enrich themselves through observation and learning. The cognitive architectures represent the infrastructure of an intelligent system that manages, through appropriate knowledge representation, perception, and in general the processes of recognition and categorization, reasoning, planning and decision-making (Langley et al., 2009). In order for the cognitive architecture to be capable of generating behaviors similar to humans, it is important to consider the role of emotions. In this way, reasoning and planning may be influenced by emotional processes and representations as happens in humans. Ideally, this could be thought of as a representation of emotional states that, in addition to influencing behavior, also helps to manage the detection and recognition of human emotions. Similarly, human intentions may somehow be linked to the expectations and beliefs of the intelligence system. In a wider perspective, the mental capabilities (Vernon et al. 2007) of artificial computational agents can be introduced directly into a cognitive architecture or emerge from the interaction of its components. The approaches presented in the literature are numerous, and range from cognitive testing of theoretical models of the human mind, to robotic architectures based on perceptual-motor components and purely reactive behaviors (see Comparative Table of Cognitive Architectures1).
Currently, cognitive architectures have had little impact on real-world applications, and a limited influence in robotics, and the humanoid. The aim and long-term goal is the detailed definition of the Artificial General Intelligence (AGI) (Goertzel, 2007), i.e. the construction of artificial systems that have a skill level equal to that of humans in generic scenarios, or greater than that of the human in certain fields. To understand the potential of existing cognitive architectures and indicate their limits, you must first begin to classify the various proposals presented in the literature. For this purpose, it is useful a taxonomy of cognitive architectures (Vernon et al. 2007; Chong et al., 2007) that identifies three main classes, for example obtained by characteristics such as memory and learning (Duch et al., 2008) . In this classification are distinguished symbolic architectures, emerging architectures, and hybrid architectures. In the following, only some architectures are discussed and briefly described, indicating some significant issues that may affect humanoids, and affective-based interactions. At present, there are no cognitive architectures that are strongly oriented to the implementation of embodied social agents, nor even were coded mechanisms to emulate the so-called social intelligence. The representation of the other, the determination of the self, including intentions, desires, emotional states, and social interactions, have not yet had the necessary consideration and have not been investigated approaches that consider them in a unified manner.
The symbolic architectures (referring to a cognitivist approach) are based on an analytical approach of high-level symbols or declarative knowledge. SOAR (State, Operator And Result) is a classic example of an expert rule-based cognitive architecture (Laird et al., 1987). The classic version of SOAR is based on a single long-term memory (storing production- rules), and a single short-term memory (with a symbolic graph structure). In an extended version of the architecture (Laird 2008), in addition to changes on short and long-term memories, was added a module that implements a specific appraisal theory. The intensity of individual appraisals (express either as categorical or numeric values) becomes the intrinsic rewards for reinforcement learning, which significantly speeds learning. (Marinier et al.,2009) presents a unified computational model that combines an abstract cognitive theory of behavior control (PEACTIDM) and a detailed theory of emotion (based on an appraisal theory), integrated in the SOAR cognitive architecture. Existing models that integrate emotion and cognition generally do not fully specify why cognition needs emotion and conversely why emotion needs cognition. Looking ahead, we aim to explore how emotion can be used productively with long-term memory, decision making module, and interactions.
The interaction is a very important aspect that makes possible a direct exchange of
![]() information, and may be relevant both for learning to perform intelligent actions. For 1Biologically Inspired Cognitive Architectures Society -Toward a Comparative Repository of Cognitive
information, and may be relevant both for learning to perform intelligent actions. For 1Biologically Inspired Cognitive Architectures Society -Toward a Comparative Repository of Cognitive
Architectures, Models, Tasks and Data. http://bicasociety.org/cogarch/example, under the notion of embodied cognition (Anderson, 2004), an agent acquires its intelligence through interaction with the environment. Among the cognitive architectures, EPIC (Executive Process Control Interactive) focuses his attention on human-machine interaction, aiming to capture the activities of perception, cognition and motion. Through interconnected processors working in parallel are defined patterns of interaction for practical purposes (Kieras & Meyer, 1997).
Finally, among the symbolic architecture, physical agents are relevant in ICARUS (Langley & Choy, 2006), integrated in a cognitive model that manages knowledge that specify the reactive abilities, reactions depending on goals and classes of problems. The architecture consists of several modules that bind in the direction of bottom-up concepts and percepts, and in a top-down manner the goals and abilities. The conceptual memory contains the definition of generic classes of objects and their relationships, and the skill memory stores how to do things.
The emergent architectures are based on networks of processing units that exploit mechanisms of self-organizations and associations. The idea behind this architecture is based on connectionism approach, which provides elementary processing units (processing element PE) arranged in a network that changes its internal state as a result of an interaction. From these interactions, relevant properties emerge, and arise from the memory considered globally or locally organized. Biologically inspired cognitive architectures distribute processing by copying the working of the human brain, and identify functional and anatomical areas correspond to human ones such as the posterior cortex (PC), the frontal cortex (FC), hippocampus (HC). Among these types of architecture, one that is widely used is based on adaptive resonance theory ART (Grossberg, 1987). The ART unifies a number of network designs supporting a myriad of interaction based learning paradigms, and address problems such as pattern recognition and prediction. ART-CogEM models use cognitive- emotional resonances to focus attention on valued goals.
Among the emerging architectures, are also considered models of dynamic systems (Beer 2000, van Gelder & Port, 1996) and models of enactive systems. The first might be more suitable for the development of high-level cognitive functions as intentionality and learning. These dynamic models are derived from the concept that considers the nervous system, body and environment as dynamic models, closely interacting and therefore to be examined simultaneously. This concept also inspired models of enactive systems, but emphasize the principle of self-production and self-development. An example is the architecture of the robot iCub (Sandini et al., 2007), that also includes principles Global Workspace Cognitive Architecture (Shanahan, 2006) and Dynamic Neural Field Architecture (Erlhagen and Bicho, 2006). The underlying assumption is that cognitive processes are entwined with the physical structure of the body and its interaction with the environment, and the cognitive learning is an anticipative skill construction rather than knowledge acquisition.
Hybrid architectures are approaches that combine methods of the previous two classes. The best known of these architectures is ACT-R (Adaptive Components of Rational-thought), which is based on perceptual-motor modules, memory modules, buffers, and pattern matchers. ACT-R (Anderson et al., 2004) process two kinds of representations: declarative and procedural: declarative knowledge is represented in form of chunks, i.e. vector representations of individual properties, each of them accessible from a labeled slot; procedural knowledge is represented in form of productions. Other popular hybrid architectures are: CLARION- The Connectionism Learning Adaptive rule Induction ON-Line (Sun, 2006), LIDA-The Learning Intelligent Distribution Agent (Franklin & Patterson, 2006).
More interesting for the purposes of this chapter is the PSI model (Bartl & Dorner, 1998; Bach et al., 2006) and its architecture that involves explicitly the concepts of emotion and motivation in cognitive processes. MicroPsi (Bach et al., 2006) is an integrative architecture based on PSI model, has been tested on some practical control applications, and also on simulating artificial agents in a simple virtual world. Similar to LIDA, MicroPsi currently focuses on the lower level aspects of cognitive process, not yet directly handling advanced capabilities like language and abstraction. A variant of MicroPsi framework is included also in CogPrime (Goertzel, B. 2008). This is a multi-representational system, based on a hyper- graphs with uncertain logical relationships and associative relations operating together. Procedures are stored as functional programs; episodes are stored in part as “movies” in a simulation engine.
Recognition of human activities and intentions
In the wider context of capturing and understanding human behavior (Pantic et al., 2006), it is important to perceive (detect) signals such as facial expressions, body posture, and movements while being able to identify objects and interactions with other components of the environment. The techniques of computer vision and machine learning methodologies enable the gathering and processing of such data in an increasingly accurate and robust way (Kelley et al., 2010). If the system captures the temporal extent of these signals, then it can make predictions and create expectations of their evolution. In this sense, we speak of detecting human intentions, and in a simplified manner, they are related to elementary actions of a human agent (Kelley et al., 2008).
Over the last few years has changed the approach pursued in the field of HCI, shifting the focus on human-centered design for HCI, namely the creation of systems of interaction made for humans and based on models of human behavior (Pantic et al., 2006). The Human- centered design, however, requires thorough analysis and correct processing of all that flows into man-machine communication: the linguistic message, non-linguistic signals of conversation, emotions, attitudes, modes by which information are transmitted, i.e. facial expressions, head movements, non-linguistic vocalizations, movements of hands and body posture, and finally must recognize the context in which information is transmitted. In general, the modeling of human behavior is a challenging task and is based on the various behavioral signals: affective and attitudinal states (e.g. fear, joy, inattention, stress); manipulative behavior (actions used to act on objects environment or self-manipulative actions like biting lips), culture-specific symbols (conventional signs as a wink or a thumbs- up); illustrators actions accompanying the speech, regulators and conversational mediators as who nods the head and smiles.
Systems for the automatic analysis of human behavior should treat all human interaction channels (audio, visual, and tactile), and should analyze both verbal and non verbal signals (words, body gestures, facial expressions and voice, and also physiological reactions). In fact, the human behavioral signals are closely related to affective states, which are conducted by both physiological and using expressions. Due to physiological mechanisms, emotional arousal affects somatic properties such as the size of the pupil, heart rate, sweating, body temperature, respiration rate. These parameters can be easily detected and are objective measures, but often require that the person wearing specific sensors. Such devices in future may be low-cost and miniaturized, distributed in clothing and environment, but which are now unusable on a large scale and in non structured situations. The visual channel that takes into account facial expressions and gestures of the body seems to be relatively more important to human judgment that recognizes and classifies behavioral states. The human judgment on the observed behavior seems to be more accurate if you consider the face and body as elements of analysis.
A given set of behavioral signals usually does not transmit only one type of message, but can transmit different depending on the context. The context can be completely defined if you find the answers to the following questions: Who, Where, What, How, When and Why (Pantic et al., 2006). These responses disambiguating the situation in which there are both artificial agent that observes and the human being observed.
In the case of human-robot interaction, one of the most important aspects to be explored in the detection of human behavior is the recognition of the intent (Kelley et al., 2008): the problem is to predict the intentions of a person by direct observation of his actions and behaviors. In practice we try to infer the result of a goal-directed mental activity that is not observable, and characterizing precisely the intent. Humans recognize, or otherwise seek to predict the intentions of others, using the result of an innate mechanism to represent, interpret and predict the actions of the other. This mechanism probably is based on taking the perspective of others (Gopnick & Moore, 1994), allowing you to watch and think with eyes and mind of the other.
The interpretation of intentions can anticipate the evolution of the action, and thus capture its temporal dynamic evolution. An approach widely used in statistical classification of systems that evolve over time, is what uses Hidden Markov Model (Duda et al., 2000). The use of HMM in the recognition of intent (emphasizing the prediction) has been suggested in (Tavakkoli et al., 2007), that draws a link between the HMM approach and the theory of the mind.
The recognition of the intent intersects with the recognition of human activity and human behavior. It differs from the recognition of the activity as a predictive component: determining the intentions of an agent, we can actually give an opinion on what we believe are the most likely actions that the agent will perform in the immediate future. The intent can also be clarified or better defined if we recognize the behavior. Again the context is important and how it may serve to disambiguate (Kelley et al., 2008). There are a pairs of actions that may appear identical in every aspect but have different explanations depending on their underlying intentions and the context in which they occur.
Both to understand the behaviors and the intentions, some of the tools necessary to address these problems are developed for the analysis of video sequences and images (Turaga et al.,2008). The aspects of security, monitoring, indexing of archives, led the development of algorithms oriented to the recognition of human activities that can form the basis for the recognition of intentions and behaviors. Starting from the bottom level of processing, the first step is to identify the movements in the scene, to distinguish the background from the rest, to limit the objects of interest, and to monitor changes in time and space. We use then, techniques based on optical flow, segmentation, blob detection, and application of space- time filters on certain features extracted from the scene.
When viewing a scene, the man is able to distinguish the background from the rest, that is, instant by instant, automatically rejects unnecessary information. In this context, a model of attention is necessary to select the relevant parts of the scene correctly. One problem may be, however, that in these regions labeled as background is contained the information that allows for example the recognition of context that allows the disambiguation. Moreover, considering a temporal evolution, what is considered as background in a given instant, may be at the center of attention in successive time instants.
Identified objects in the scene, as well as being associated with a certain spatial location(either 2D, 2D and 1/2, or 3D) and an area or volume of interest, have relations between them and with the background. So the analysis of the temporal evolution of the scene, should be accompanied with a recognition of relationships (spatial, and semantic) between the various entities involved (the robot itself, humans, actions, objects of interest, components of the background) for the correct interpretation of the context of action. But defining the context in this way, how can we bind the contexts and intentions? There are two possible approaches: the intentions are aware of the contexts, or vice versa the intentions are aware of the contexts (Kelley et al., 2008). In the first case, we ranked every intention carries with it all possible contexts in which it applies, and real-time scenario is not applicable. The second approach, given a context, we should define all the intentions that it may have held (or in a deterministic or probabilistic way). The same kind of reasoning can be done with the behaviors and habits, so think of binding (in the sense of action or sequence of actions to be carried out prototype) with the behaviors.
A model of intention should be composed of two parts (Kelley et al, 2008): a model of activity, which is given for example by a particular HMM, and an associated label. This is the minimum amount of information required to enable a robot to perform disambiguation of context. One could better define the intent, noting a particular sequence of hidden states from the model of activity, and specifying an action to be taken in response. A context model, at a minimum, shall consist of a name or other identifier to distinguish it from other possible contexts in the system, as well as a method to discriminate between intentions. This method may take the form of a set of deterministic rules, or may be a discrete probability distribution defined on the intentions which the context is aware.
There are many sources of contextual information that may be useful to infer the intentions, and perhaps one of the most attractive is to consider the so-called affordances of the object, indicating the actions you can perform on it. It is possible then builds a representation from probabilities of all actions that can be performed on that object. For example, you can use an approach based on natural language (Kelley et al., 2008), building a graph whose vertices are words and a label is the weighed connecting arc indicating the existence of some kind of grammatical relationship. The label indicates the nature of the relationship, and the weight can be proportional to the frequency with which the pair of words exists in that particular relationship. From such a graph, we can calculate the probability to determine the necessary context to interpret an activity. Natural language is a very effective vehicle for expressing the facts of the world, including the affordances of the objects.
If the scene is complex, performance and accuracy can be very poor when you consider all the entities involved. then, can be introduced for example the abstraction of the interaction space, where each agent or object in the scene is represented as a point in a space with a defined distance on it related to the degree of interaction (Kelley et al, 2008). In this case, then consider the physical artificial agent (in our case the humanoid) and its relationship with the space around it, giving more importance to neighboring entities to it and ignore those far away.
Detection of human emotions
Detection of human emotions plays many important roles in facilitating healthy and normal human behavior, such as in planning and deciding what further actions to take, both in interpersonal and social interactions. Currently in the field of human-machine interfaces, systems and devices are now being designed that can recognize, process, or even generate emotions (Cerezo et al., 2008). The “affect recognition” often requires a multidisciplinary and multimodal approach (Zeng et al., 2009), but an important channel that is rich with information is facial expressiveness (Malatesta et al., 2009). In this context, the problem of expression detection is supported by robust artificial vision techniques. Recognition has proven critical in several aspects: such as in defining basic emotions and expressions, the subjective and cultural variability, and so on.
Consideration must be given the more general context of affect, for which research in psychology has identified three possible models: categorical, dimensional and appraisal- based approach (Grandjean et al., 2008). The first approach is based on the definition of a reduced set of basic emotions, innate and universally recognized. This model is widely used in automatic recognition of emotions, but as well as for human actions and intentions, can be considered more complex models that address a continuous range of affective and emotional states (Gunes et al., 2011). Dimensional models are described by geometric spaces that can use the basic emotions, but represented by a continuous dynamic dimensions such as arousal, valence, expectation, intensity. The appraisal-based approach requires that the emotions are generated by a continuous and recursive evaluation and comparison of an internal state and the state of the outside world (in terms of concerns, needs, and so on). Of course this model is the most complex to achieve the recognition, but is used for the synthesis of virtual agents (Cerezo et al., 2008).
As mentioned previously, most research efforts on the recognition and classification of human emotions (Pantic et al., 2006) focused on a small set of prototype expressions of basic emotions related to analyzing images or video, and analyzing speech. Results reported in the literature indicate that typically performances reach an accuracy from 64% to 98%, but detecting a limited number of basic emotions and involving small groups of human subjects. It is appropriate to identify the limitations of this simplification. For example, if we consider the dimensional models, it becomes important to distinguish the behavior of the various channels of communication of emotion: the visual channel is used to interpret the valence, and arousal seems to be better defined by analyzing audio signals. By introducing a multi- sensory evaluation of emotion, you may have problems of consistency and masking, i.e. that the various communication channels indicate different emotions (Gunes et al., 2011).
Often the emotion recognition systems have aimed to the classification of emotional expressions deduced from static and deliberate, while a challenge is on the recognition of spontaneous emotional expressions (Bartlett, et al. 2005; Bartlett, et. Al. 2006 ; Valstar et al.,2006), i.e. those found in normal social interactions in a continuous manner (surely dependent on context and past history), capable of giving more accurate information about affective state of human involved in a real communication (Zeng et al., 2009).
While the automatic detection of the six basic emotions (including happiness, sadness, fear, anger, disgust and surprise) can be done with reasonably high accuracy, as they are based on universal characteristics which transcend languages and cultures (Ekman, 1994), spontaneous expressions are extremely variable and are produced – by mechanisms not yet fully known – by the person who manifests a behavior (emotional, but also social and cultural), and underlies intentions (conscious or not).
If you look at human communication, some information is related to affective speech, and in particular to the content. Some affective mechanisms of transmission are clear and directly related to linguistics, and other implicit (paralinguistic) signals that may affect especially the way in which words are spoken. You can then use some of the dictionaries that can link the word to the affective content and provide the lexical affinity (Whissell, 1989). In addition, you can analyze the semantic context of the speech to determine more emotional content, or endorse those already detected. The affective messages transmitted through paralinguistic signals, are primarily affected by prosody (Juslin & Scherer, 2005), which may be indicative of complex states such as anxiety, boredom, and so on. Finally, are also relevant non- linguistic vocalizations such as laughing, crying, sighing, and yawning (Russell et al., 2003). Considering instead the channel visual, emotions arise from the following aspects: facial expressions, movements (actions) facial movements and postures of the body (which may be less susceptible to masking and inconsistency).
Most of the work on the analysis and recognition of emotions is based on the detection of facial expressions, addressing two main approaches (Cohn, 2006; Pantic & Bartlett, 2007): the recognition based on elementary units of facial muscles action (AU), that are part of the coding system of facial expression called the Facial Action coding – FACS (Ekman & Friesen
1977), and recognition based on spatial and temporal characteristics of the face.
FACS is a system used for measuring all visually distinguishable facial movements in terms of atomic actions called Facial Action Unit (AU). The AU is independent of the interpretation, and can be used for any high-level decision-making process, including the recognition of basic emotions (Emotional FACS – EMFACS2), the recognition of various emotional states (FACSAID – Facial Action Coding System Affect Interpretation Dictionary2), and the recognition of complex psychological states such as pain, depression, etc.. The fact of having a coding, has originated a growing number of studies on spontaneous behavior of the human face based on AU (e.g., Valstar et al., 2006).
The facial expression can also be detected using various pattern recognition approaches based on spatial and temporal characteristics of the face. The features extracted from the face can be geometric shapes such as parts of the face (eyes, mouth, etc.), or location of salient points (the corners of the eyes, mouth, etc.), or facial characteristics based on global appearance and some particular structures, such as wrinkles, bulges, and furrows. Typical examples of geometric feature-based methods are those that face models described as set of reference points (Chang et al., 2006), or characteristic points of the face around the mouth, eyes, eyebrows, nose and chin (Pantic & Patras, 2006), or grids that cover the whole region of the face (Kotsia & Pitas, 2007). The combination of approaches based on geometric features and appearance is likely (eg Tian et al., 2005) the best solution for the design of systems for automatic recognition of facial expressions (Pantic & Patras, 2006). The approaches based on 2D images of course suffer from the problem of the point of view, which can be overcome by considering 3D models of the human face (eg, Hao & Huang, 2008; Soyel & Demirel, 2008, Tsalakanidou & Malassiotis, 2010).
Integration of a humanoid vision agent in PSI cognitive architecture
SeARCH-In (Sensing-Acting-Reasoning: Computer understands Human Intentions) is an intentional vision framework scheme oriented towards human-humanoid interactions (see figure 1). It extends on the system presented in the previous work (Infantino et al., 2008), improving vision agent and expressiveness of the ontology. Such a system will be able to recognize user faces, to recognize and track human postures by visual perception. The described framework is organized on two modules mapped on the corresponding outputs to obtain intentional perception of faces and intentional perception of human body movements. Moreover a possible integration of an intentional vision agent in the PSI (Bart & Dorner, 1998; Bach et al., 2006) cognitive architecture is proposed, and knowledge management and reasoning is allowed by a suitable OWL-DL ontology.
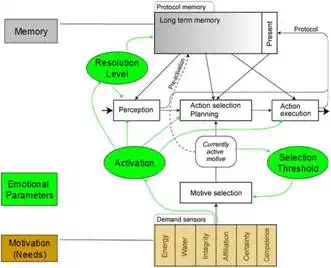
Fig. 1. Cognitive-emotional-motivational schema of the PSI cognitive architecture3.
In particular, the ontological knowledge approach is employed for human behavior and expression comprehension, while stored user habits are used for building a semantically meaningful structure for perceiving human wills. A semantic description of user wills is formulated in terms of the symbolic features produced by the intentional vision system. The sequences of symbolic features belonging to a domain specific ontology are employed to infer human wills and to perform suitable actions.
Considering the architecture of PSI (see Figure 1) and the intentional vision agent created by the SEARCH-In framework, you can make some considerations on the perception of the intentions of a human being, the recognition of his identity, the mechanism that triggers of sociality, how memory is used, the symbolic representation of actions and habits, and finally the relationship of the robot’s inner emotions and those observed.
The perception that regards the agent is generated from the observation of a human being who acts in an unstructured environment: human face, body, actions, and appearance are the object of humanoid in order to interact with him. The interaction is intended to be based on emotional and affective aspects, on the prediction of intents recalled from the memory and observed previously. Furthermore, the perception concerns, in a secondary way for the moment, the voice and the objects involved in the observed action.
![]() The face and body are the elements analyzed to infer the affective state of the human, and for the recognition of identity. The face is identified in the scene observed by the cameras of the robot using the algorithm of Viola-Jones (Viola & Jones, 2004), and its OpenCV4 implementation. The implementation of this algorithm is widely used in commercial devices since it is robust, efficient, and allows real-time use. The human body is detected by the Microsoft Kinect device, which is at the moment is external to humanoid, but the data are accessible via the network. From humanoid point of view, the Kinect5 device is in effect one
The face and body are the elements analyzed to infer the affective state of the human, and for the recognition of identity. The face is identified in the scene observed by the cameras of the robot using the algorithm of Viola-Jones (Viola & Jones, 2004), and its OpenCV4 implementation. The implementation of this algorithm is widely used in commercial devices since it is robust, efficient, and allows real-time use. The human body is detected by the Microsoft Kinect device, which is at the moment is external to humanoid, but the data are accessible via the network. From humanoid point of view, the Kinect5 device is in effect one
4http://opencv.willowgarage.com/wiki/
5http://en.wikipedia.org/wiki/Kinect
of its sensor, and the software architecture integrated it as the other sensors. Again, you are using a device that is widely used, and that ensures accurate perceptive results in real time. This sensor produces both a color image of the scene, and a depth map, and the two representations are aligned (registered), allowing you to associate each pixel with the depth estimated by IR laser emitter-detector pair. Through software libraries, it is possible to reconstruct the human posture, through a reconstructed skeleton defined as a set of points in three dimensional space corresponding to the major joints of the human body.
In the region of the image containing the detected face, are run simultaneously two sets of algorithms. The first group is used to capture the facial expression, identifying the position and shape of the main characteristic features of the face: eyes, eyebrows, mouth, and so on. The recognition of the expression is done using the 3D reconstruction (Hao Tang & Huang,
2008), and identifying the differences from a prototype of a neutral expression (see figure 3). The second group, allows the recognition, looking for a match in a database of faces, and using the implementation (API NaoQi, ALFaceDetection module) already available to the NAO humanoid robot (see figure 2).
The PSI model requires that the internal emotional states modulate the perception of the robot, and are conceived as intrinsic aspects of the cognitive model. The emotions of the robots are seen as an emergent property of the process of modulation of the perceptions, behavior, and global cognitive process. In particular, emotions are encoded as configuration settings of cognitive modulators, which influence the pleasure/distress dimension, and on the assessment of the cognitive urges.
The idea of social interaction based on affect recognition and intentions, that is the main theme of this chapter, simply leads to a first practical application of cognitive theory PSI. The detection and recognition of a face meets the need for social interaction that drives the humanoid robot, consistent with the reference theory which deals with social urges or drives, or affiliation. The designed agent includes discrete levels of pleasure/distress: the greatest pleasure is associated with the fact that the robot has recognized an individual, and has in memory the patterns of habitual action (through representations of measured movement parameters, normalized in time and in space, and associated with a label); the lowest level when it detects a not identified face, showing a negative affective state, and a lack of recognition and classification of the observed action. It is possible to implement a simple mechanism of emotional contagion, which executes the recognition of human affective state (limited to an identified human), and tends to set the humanoid on the same mood (positive, neutral, negative). The Nao may indicate his emotional state through the coloring of some leds placed in eyes and ears, and communicates its mood changes by default vocal messages to make the human aware of its status (red is associated with a state of stress, green with neutral state, yellow with euphoria, blue with calm).
The symbolic explicit representation provided by the PSI model requires that the objects, situations, plans are described by a formalism of executable semantic networks, i.e. semantic networks that can change their behaviors via messages, procedures, or changes to the graph. In previous work (Infantino et al., 2008), it has been defined a reference ontology (see figure3) for the intentional vision agent which together with the semantic network allows for two levels of knowledge representation, increasing the communicative and expressive capabilities.
The working memory, in our example of emotional interaction, simply looks for and identifies human faces, and contains actions for random walk and head movements to allow it to explore space in its vicinity until it finds a human agent to interact with. There is not a world model to compare with the one perceived, even if the reconstructed 3D scene by depth sensor could be used, and compare it with a similar internal model in order to plane exploration through anticipation in the cognitive architecture. The long-term memory is represented by the collection of usual actions (habits), associated with a certain identity and emotional state, and in relation to certain objects. Again, you might think to introduce simple mechanisms affordances of objects, or introduce a motivational relevance related to the recognition of actions and intentions.

Fig. 2. NAO robot is the humanoid employed to test the agent that integrates SeARCH-In framework and PSI cognitive model.
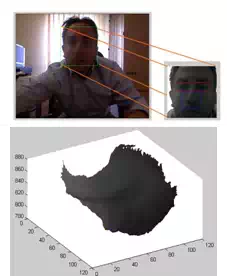

Fig. 3. Example of face and features extraction, 3D reconstruction for expression recognition
(on the left), and 3D skeleton of human (on the right).
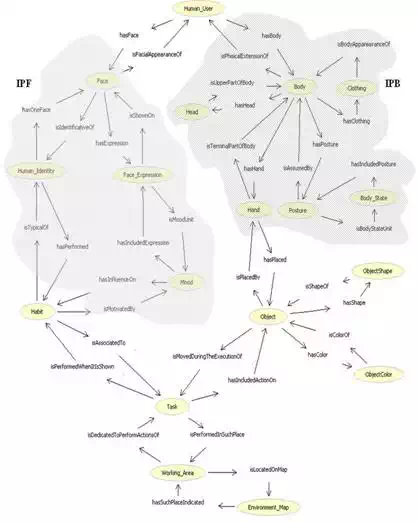
Fig. 4. SearchIn Ontology (see Infantino et al., 2008). Gray areas indicate Intentional
Perception of Faces module (IPF) and Intentional Perception of Body module (IPB).


Comments are closed